二叉树遍历算法
- Published on
二叉树的遍历(traversing binary tree)是指从根结点出发,按照某种次序依次访问二叉树中所有的结点,使得每个结点被访问依次且仅被访问一次。
对于二叉树,有深度遍历和广度遍历,深度遍历有前序、中序以及后序三种遍历方法,广度遍历即我们平常所说的层次遍历。
- 创建二叉树
// 定义结点TreeNode类
class TreeNode {
node
left
right
constructor(node) {
this.node = node
this.left = null
this.right = null
}
}
// 前序遍历生成二叉树
const creatTree = (list) => {
const n = list.length
if (n === 0) {
return null
}
const node = new TreeNode(list[0])
// 分割数组
const index = (n - 1) / 2 + 1
const left = list.slice(1, index)
const right = list.slice(index)
node.left = creatTree(left)
node.right = creatTree(right)
return node
}
creatTree(['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I'])
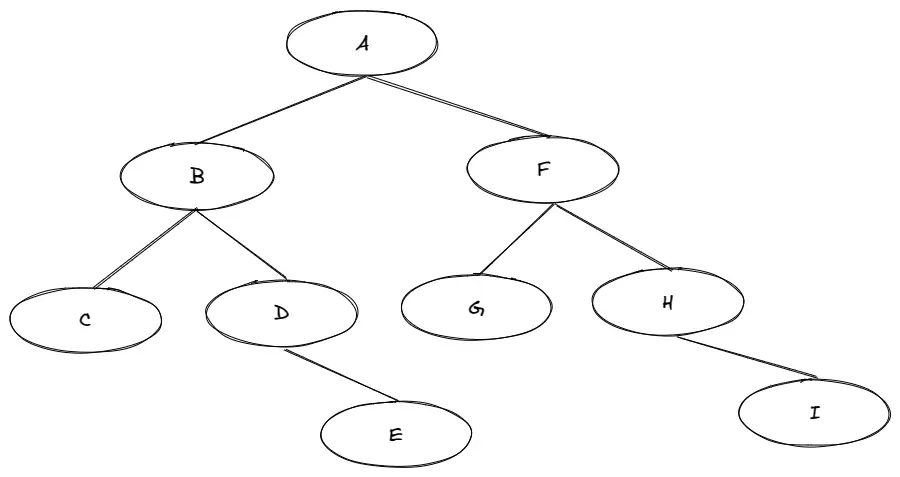
- 前序遍历(DLR)
先访问根结点,然后前序遍历左子树,再前序遍历右子树。
// 递归遍历
const getDLR = (tree, DLR) => {
if (tree) {
DLR.push(tree.node)
getDLR(tree.left, DLR)
getDLR(tree.right, DLR)
}
return DLR
}
getDLR(tree, [])
// 非递归遍历
const getDLR = (tree, DLR) => {
if (tree) {
const stack = [tree] // 将二叉树压入栈
while (stack.length !== 0) {
tree = stack.pop() // 取栈顶
DLR.push(tree.node)
// 先右后左,栈是先进后出
if (tree.right) stack.push(tree.right) // 把右子树入栈
if (tree.left) stack.push(tree.left) // 把左子树入栈
}
}
return DLR
}
getDLR(tree, [])
// ['A','B','C','D','E','F','G','H','I']
- 中序遍历(LDR)
中序遍历结点的左子树,然后访问根结点,再中序遍历右子树。
// 递归遍历
const getLDR = (tree, LDR) => {
if (tree) {
getLDR(tree.left, LDR)
LDR.push(tree.node)
getLDR(tree.right, LDR)
}
return LDR
}
getLDR(tree, [])
// 非递归遍历
const getLDR = (tree, LDR) => {
if (tree) {
const stack = [] // 建空栈
// 如果栈不为空或结点不为空,则循环遍历
while (stack.length !== 0 || tree) {
//如果结点不为空
if (tree) {
stack.push(tree) // 将结点压入栈
tree = tree.left // 将左子树作为当前结点
} else {
tree = stack.pop() // 将结点取出
LDR.push(tree.node)
tree = tree.right // 将右结点作为当前结点
}
}
}
return LDR
}
getLDR(tree, [])
// ['C','B','D','E','A','G','F','H','I']
非递归中序算法的思想就是,把当前节点入栈,然后遍历左子树,如果左子树存在就一直入栈,直到左子树为空,访问但前节点,然后让右子树入栈。
- 后序遍历(LRD)
从左到右先叶子后结点的方式遍历左右子树,最后访问根结点。
// 递归遍历
const getLRD = (tree, LRD) => {
if (tree) {
getLRD(tree.left, LRD)
getLRD(tree.right, LRD)
LRD.push(tree.node)
}
return LRD
}
getLRD(tree, [])
// 非递归遍历
const getLRD = (tree, LRD) => {
if (tree) {
const stack = [tree] // 将二叉树压入栈
let tmp = null // 定义缓存变量
while (stack.length !== 0) {
tmp = stack[stack.length - 1] // 将栈顶的值保存在tmp中
// 如果存在左子树,node !== tmp.left && node !== tmp.righ 是为了避免重复将左右子树入栈
if (tmp.left && tree !== tmp.left && tree !== tmp.right) {
stack.push(tmp.left) // 将左子树结点压入栈
} else if (tmp.right && tree !== tmp.right) {
// 如果结点存在右子树
stack.push(tmp.right) // 将右子树压入栈中
} else {
const out = stack.pop().node
LRD.push(out)
tree = tmp
}
}
}
return LRD
}
getLRD(tree, [])
// ['C','E','D','B','G','I','H','F','A']
这里使用了一个 tmp 变量来记录上一次出栈、入栈的结点。思路是先把根结点和左树推入栈,然后取出左树,再推入右树,取出,最后取根结点。
下面是用这个算法遍历二叉树的过程:
| step | stack | tmp | tree | out |
|---|---|---|---|---|
| init | A | null | A | |
| 1 | AB | A | A | |
| 2 | ABC | B | A | |
| 3 | AB | C | C | C |
| 4 | ABD | B | C | |
| 5 | ABDE | D | C | |
| 6 | ABD | E | E | E |
| 7 | AB | D | D | D |
| 8 | A | B | B | B |
| 9 | AF | A | B | |
| 10 | AFG | F | B | |
| 11 | AF | G | G | G |
| 12 | AFH | F | G | |
| 13 | AFHI | H | G | |
| 14 | AFH | I | I | I |
| 15 | AF | H | H | H |
| 16 | A | F | F | F |
| 17 | AFH | F | ||
| 18 | A | A | A |
- 层次遍历
从根结点从上往下逐层遍历,在同一层,按从左到右的顺序对结点逐个访问。
const breadthTraversal = (tree, BRT) => {
if (tree) {
const queue = [tree] // 将二叉树放入队列
while (queue.length !== 0) {
tree = queue.shift() // 从队列中取出一个结点
BRT.push(tree.node)
// 如果存在左子树,将左子树放入队列
if (tree.left) queue.push(tree.left)
// 如果存在右子树,将右子树放入队列
if (tree.right) queue.push(tree.right)
}
}
return BRT
}
breadthTraversal(tree, [])
// ['A','B','F','C','D','G','H','E','I']
使用数组模拟队列,首先将根结点归入队列。当队列不为空时,执行循环:取出队列的一个结点,如果该节点有左子树,则将该节点的左子树存入队列;如果该节点有右子树,则将该节点的右子树存入队列。
以上就是本文的全部内容,感谢阅读。